TransVar
A computer-driven study of Slavic varieties in Transcarpathian region
Slavic in Transcarpathian region
Slavic people have inhabited the Carpathian mountains for a very long time, most probably, since their initial dispersal in Central and Eastern Europe in the beginning of CE, and till the current day. Nowadays Transcarpathian Slavic is a diverse group that include a plethora varieties that span from south-eastern Ukrainian Hutsul and all the way to the Central Slovak and Polish Spisz. While their origins lie in the branches of the Slavic family tree that have split long ago, they share a suprisingly large set of common features that joins them in an areal grouping.
The current stage of the project concentrates on the eastern part of this continuum, small territorial southern varieties of Ukrainian: Bojko, Central Transcarpathian, Hutsul and Lemko. It uses computational methods to study their linguistic peculiarities, both the ones that show the contact within the Carpathian area, and those that hint at their common Pre-Proto-Ukrainian stage of development. The main approach is computer-driven. I use a pre-trained on Modern Standard Ukrainian model to highlight on-going variation and change, analyze it with statistical methods, and apply the results for developing a new model that specifically deals with the varieties in question.
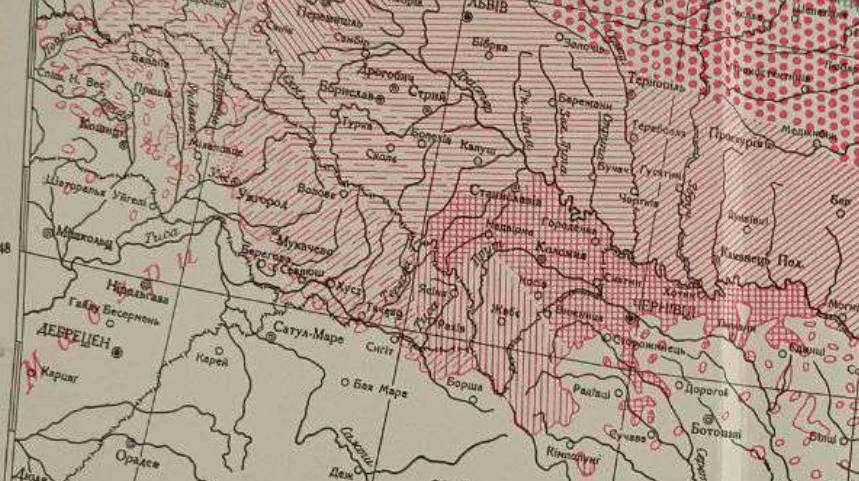
A map of Transcarpathian lects distribution in the beginning of the twentieth century, taken from Ziłyński (1933).
Language polymorphism
The key to performing a computer-driven study is the concept of language polymorphism markers. Language polymorphism is a result of on-going variation and/or change processes within a population that lead to appearance of significant differences in individual variants of speakers. Language polymorphism are sequences of language units that signal these processes. In phonetic or grammar features-based study, these are character-based isoglosses: the differences in historical development of sounds, morphemes or syntactic structures. In word list-based study, language polymorphism manifests itself through mismatches for particular concepts (words that have almost identical meaning do not come from a single word historically, like German Berg and English mountain), different affixation patterns (in some Slavic varieties, one can often meet words like solnyško ‘sun + little’ as a neutral word for sun, while in others the diminutive suffix -yšk-/-išk- is absent), and regular phonetic correspondences, detected across all the words.
The challenge of this research is to understand, what are language polymorphism markers in non-parallel corpora, the collections of utterances that do not provide a researcher with strict one-to-one correspondences. The hypothesis is the following: it is possible to use the results of processing the corpus of a lect with language models designed for close relatives of this lect to highlight the distributional peculiarities of signals within the lect.
The key tool for the exploration is the heatmap-based visualisation. It is based on the errata in the automatic modelling (for instance, incorrect part-of-speech tagging), and its aim is to highlight the specific places in the texts of the corpus, where it is the most likely to meet some kind of on-going variation and change. Look, for example, to the results of lemmatising Lemko data with Modern Standard Ukrainian-trained tagger:
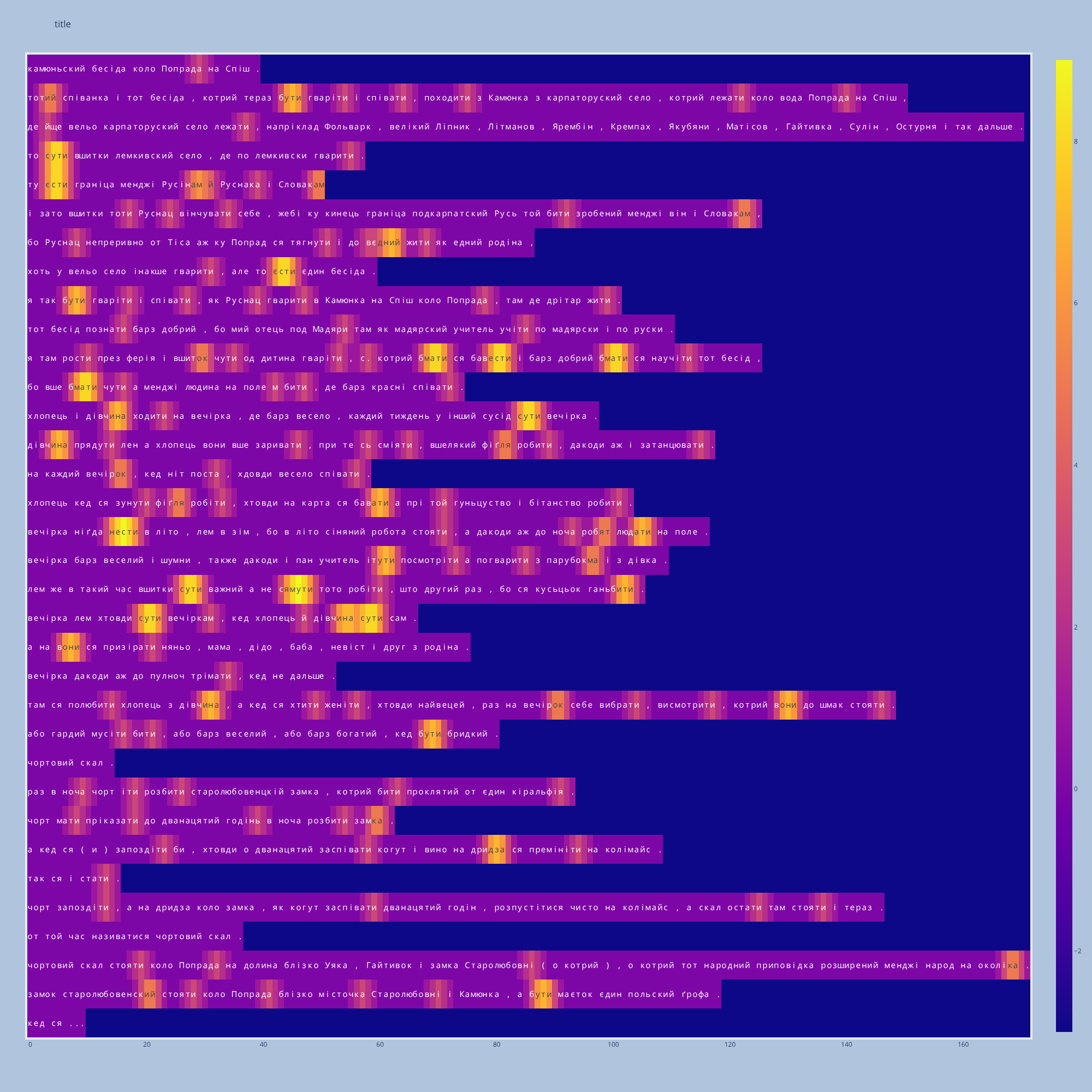
Here, one can visibly see hot spots, where the errata concentrate. These are mostly verbs, and there is a reason for this: the distribution of auxiliary verbs (specifically, byti ‘to be’), similar to English ‘be’ or ‘have’ in Continious and Perfect structures, in Lemko significantly differs, there are much more overt copula structures (“These are all Lemko villages”; Modern Standard Ukrainian tends to have something more similar to “These — Lemko villages”), which confuses tagger and signals at the presence of polymorphism. The project dedicates itself to studying such cases.
Material
After the events of the twentieth century that left their trace in the Transcarpathian region, namely, two World Wars, a series of local conflicts, alongside with several acts of genocide and forced resettlement, the linguistic landscape that existed at the end of the nineteenth century is gone. The only way to reconstruct even the small pieces of information about this world is to extract the texts from the archives, the texts that portray not only speakers and their culture, but also researchers and their culture. There are collections of dialect recordings transcriptions that are not digitised, and, therefore, are underreserached. This is not just a loss for the science of linguistics, this is a loss for the communities that inherit and follow the communities that were the agents of the original study.
Because, after all, this was a communal effort. The collectors of the material, their scientific advisors and colleagues were either Ukrainians, and most of them Ukrainians from the Transcarpathian region, or the people deeply interested not just in the linguistic data, but the cultural practices, social interactions and personal stories that these data preserved for the future generations: wedding ceremonies, relationships between grandparents and grandchildren, contacts between villages, cities, and even countries. Modern community is going to need it even more now, because of so many tragic events that happened to it. Should the people who inherit this culture and this language (in the widest sense possible) seek to know more, this material must be accessible to them.
At the current stage of the project, there are four collections of data that I intend to digitise as thoroughly as possible. Below I shortly introduce each of them; I hope that there will be a possibility to digitise them in full. Not only as the collection of the materials: these are crucial steps in the history of the Ukrainian (and Slavic in general) dialectology that manifested the shift from differentiating perspective that treated small territorial lects as either inferior or, at best, supplementary to national standards, to the integrative perspective that started considering them as independent enitites of their own.
Hnatjuk (1912) — Essentials of Ukrainian Demonology

A cover of Hnatjuk (1912).
The title of Hnatjuk (1912) is Знадоби до украïнськоï демонольоѓіï ‘Essentials of Ukrainian Demonology’. The work is the result of a collective effort by several academic scholars working for the ethnographic commission of their organisation, the </i>Наукове товариство імени Шевченка</i> (‘Taras Shevchenko Scientific Society’), which still exists in Ukraine. It contains texts recorded from speakers of small territorial lects during field trips conducted at the beginning of the twentieth century. There are fifteen groups of texts, each containing stories on a particular topic: mostly different kinds of supernatural creatures, but also human fears connected to supernatural elements and hidden mystical treasures. The graphic system of the work is standard Ukrainian Cyrillic of the time, the main characteristics being the simultaneous use of the graphemes ⟨i⟩, ⟨и⟩, and ⟨ï⟩, as well as the use of ⟨ў⟩.
There is no overarching narrative that links the texts or groups, nor is there any analysis or linguistic characterisation of the lects. Still, metalinguistic information is present. It includes the date and place of recording, the name of the recorded person, and, in some cases, the name of the person who carried out the recording. The work lacks crucial sociolinguistic information (age, education, occupation, and a description of the linguistic repertoire) that is present in linguistic works on small territorial lects from a slightly later period. Nevertheless, for the purposes of preliminary analysis and given the lower degree of societal mobility at the time, the place of recording is the key type of information, and this information alone suffices.
The very important feature is the presence of ethnographic description and summarisation of the material provided. This facilitates a better understanding not only of the supernatural entities themselves, but also of how they fit into a broader typological (at least European) context. While these data are of utmost importance for ethnographic research, they are not of direct use for the analysis of the informants’ lects. However, differences in the graphical representation of similar words (especially function words such as prepositions, particles, conjunctions, and auxiliaries) between the descriptive sections and the recorded material, if present, may signal that the scholars who recorded the folklore tales did so faithfully with respect to the linguistic component.
Nakonečna and Rudnyc’kyj (1940) — Ukrainian Dialects: South-Western Ukrainian

A cover of Nakonečna and Rudnyc’kyj (1940).
Ukrainische Mundarten: Südkarpatoukrainisch ; (Lemkisch, Bojkisch und Huzulisch) ‘Ukrainian Dialects: South-Western Ukrainian (Lemko, Bojko and Hutsul)’ is a rather short book, yet it characterises Lemko, Bojko, and Hutsul in a rather detailed manner, especially from the phonetic point of view. It gives a general linguistic introduction, accompanied by the metadata of the speakers. It also contain texts and a short dictionary of the lexical items from all of the studied lects: Kamjunka Lemko, Užhorod Bojko, and Vovčyneć Hutsul. The key advantage of this book, and, at the same time, the most challenging part for a person who decides to digitise it, is an extremely detailed phonetic transcription of the material.
There are two key issues: the fact that the detailed description of the system is in the other book (Zilyn’skyj 1933), and the absence of non-textual data (recordings, and, crucially, as we are going to see later, palatograms, the ultrasound photographs of the person in the process of articulating sounds). The former is lesser of a problem, while the latter is crucial. The author of the original transcription, the famous Ukrainian dialectologist I. Zilyn’skyj, claims that some of the sounds that are distinguished by articulation, but not by acoustic characteristics. This raises two questions: how did the research distinguish between these sounds, while transcribing them, and, more crucially, how it is possible to do so today. Unfortunately, there are no answer to both, so I decided to just convert this to IPA as is to ensure the preservation.
However, Nakonečna and Rudnyc’kyj (1940) represent their data with two more layers: standardised transcription and German translation. These are much more reliable, as, paradoxically, they are much more approximate and depicted only those features of the data that the scholars considered to be of the utmost importance. Standardised Ukrainian transcription of Nakonečna and Rudnyc’kyj (1940) has thus become the main data representation way in the corpus. It is mostly understandable for the modern speakers, tools of natural language processing (NLP), large language models (LLMs) and more traditional approaches alike. There are clear correspondences between the sets of sounds from the phonetic transcription and the graphemes of the standardised transcription that makes the latter the reliable approximation of the former that erases the most problematic contrasts, giving a modern scholar an idea of the articulation place, but not pinpointing them to the possibly wrong exact position. Below you see the initial structure of the data in Nakonečna and Rudnyc’kyj (1940).
| to sut fʂˈɯtkɤ̝ lemkˈʊ̈wskɤ̝ sˈelɑ de po lemkˈʊ̈wskɤ̝ ɦwˈɑrjɑt // |
| То сут вши́тки лемки́вски сéла, де по лемки́вски гва́рят. |
| Das sind alles lemkische Dörfer, wo lemkisch gesprochen wird. |
Nakonečna and Rudnyc’kyj (1940) overall becomes a basis for the digitisation of the other resources, hinting at the potential issues that are inevitably going to arise and the ways to circumvent or mitigate them. At the same time the work on it leads to the development of the reliable template for all the other sources, which are not as well rendered as this book.
Kuraszkiewicz (1963) — A sketch of eastern Slavic dialectology

A cover of Kuraszkiewicz (1940).
Kuraszkiewicz (1963), Zarys dialektologii wschodniosłowiańskiej z wyborem tekstów gwarowych ‘A sketch of eastern Slavic dialectology with a sample of dialect texts ‘ on the contrary to Nakonečna and Rudnyc’kyj (1940), primarily concentrates on the wide-scale study of all the eastern Slavic small territorial lect groups, as well as their overarching literary standards. It contains a rather extensive description for each of these groups, but, crucially, texts, recorded at the corresponding territories. Among these texts there are some representatives of the Transcarpathian lects, recorded and transcribed mostly at the beginning of the XX century.
It is rather hard to digitise the texts from Kuraszkiewicz (1963). The explanation of transcription system is absent, and it takes effort (and auxiliary material) to make a proper correspondence between it and IPA, or even standard Ukrainian. Any signs of a standard-based additional transcription or a translation into any other language, let alone Standard Ukrainian, is absent. Once again, there are no audio recordings. The crucial issue, however, is the lack of metadata, aside from the group (Bojko/Central Transcarpathian/Hutsul/Lemko) and the source of transcription, including the dialectologist’s name. The precise location of the recordign is also in the data. This helps to understand, how different re- searchers represented different varieties; however, studying the varieties themselves is going to be significantly complicated in the absence of sociolinguistic data: there is no guarantee that a person grew up in the village they were recorded in. While, of course, this certainly was the time when the dialectologists searched for the most archaic features, the lack of certainty is rather problematic.
Still, even if Kuraszkiewicz (1963) is not exactly rich with metalinguistic and linguistic information, there is still one crucial advantage: a diversity of material. There are at least two texts for each of the bigger group (Bojko, Central Transcarpathian, Hutsul and Lemko). This is much needed in the dataset that otherwise is rather restrictive in terms of geographical coverage.
Zheguc (2001) — Selected texts from the Hutsul dialect in Transcarpathia

A cover of Zheguc (2001).
Zheguc (2001), Вибрані тексти з гуцульського говору в Закарпатті ‘Selected texts from the Hutsul dialect in Transcarpathia’ is a collection of texts, gathered in different time periods (beginning at the end of the twentieth century) in the Hutsul part of the Transcarpathian region. It strikingly differs in terms of the transcription system of texts. It is standardised phonetic/phonematic transcription, based on standard Ukrainian. However, it depicts the crucial features of the Transcarpathian lects, even if omitting all the phonetic nuances and inter-idiolect variation. Pivotally, there is even the description of the phonetic features of the lects.
As for sociolinguistics, Zheguc (2001) follows very much standard procedures, containing information about the speakers (age, occupation, level of education, name) and the dialectologist who had initially recorded the texts, Ivan Paňkevyč, which is extensive by the terms of the dataset. This opens the floor not only for the variationist study, but the discussion of how scholars choose to represent a non-standard variety.
The representation of the texts is not the most detailed among the other resources, but the quality of the material is arguably the best one. The transcription system is very transparent, and the sociolinguistic information is abundant. There was no choice of not including this data in the corpus.
Project navigation
The full description of the project is currently a work in progress, as both data preprocessing and research itself are in the process of iterative extension: I add more data to the corpus, conduct more experiments, and thus acquire a more precise snapshot of both linguistic varieties and the human beings that spoke these varieties each day.
Publications
Afanasev, Ilia. 2026. TransVar – the Corpus for Variation and Change Study of the Historical Transcarpathian lects. Proceedings of Workshop on Dialects in NLP — A Resource Perspective (DialRes) @ LREC 2026, Palma de Mallorca, Spain, 2026. 195–208. 💾 Download
Afanasev, Ilia. 2026. Quantitative Lect Description: A Case Study of Lemko from the Field Data of 1920s-1930s. Proceedings of the Fifth Workshop on NLP Applications to Field Linguistics, Rabat, Morocco, 2026. 46–59. 💾 Download
Afanasev, Ilia. 2026. Evaluation Framework for Transfer Learning between Closely Related Lects: A Case Study of Lemko. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects (VarDial 2026), Rabat, Morocco, 2026. 304–316. 💾 Download
Afanasev, Ilia. 2025. Computer-assisted Study of Historical Lemkian (Transcarpathian) Lects: Basic Vocabulary Approach. Scripta and e-Scripta 25, 2025. 11-24.
Talks
Corpus-level comparison of eastern Transcarpathian Slavic varieties. Slavistisch-linguistisches Kolloquium, Albert-Ludwigs-Universität Freiburg, Freiburg im Breisgau, 20.05.2026 (online). 💾 Download
References
- Salvatore Del Gaudio. 2017. An introduction to Ukrainian dialectology. Linguistische Reihe Sonderband 94. Peter Lang, Frankfurt am Main Bern Wien.
- Hnatjuk, V. 1912. Znadobi do ukraïns’koї demonol’ogìï. Zìbrav Volodimir Gnatûk. Tom ÌÌ. Vipusk 1 [Materials for Ukrainian Demonology. Collected by Volodymyr Hnatiuk. Vol. II. Issue 1] // Etnografìčnij z̀bìrnik / Vidaè Etnografìčna komìsìia Naukovogo tovaristva ìmeni Ševčenka. L’vìv, 1912. Tom HHHÌ.
- Władysław Kuraszkiewicz. 1963. Zarys dialektologii wschodniosłowiańskiej z wyborem tekstów gwarowych, wyd. 2., zmien. i rozsz. edition. Państwowe Wydawn. Naukowe, Warszawa.
- Johann-Mattis List. 2016. Beyond cognacy: historical relations between words and their implication for phylogenetic reconstruction, </i>Journal of Language Evolution</i>, 1(2): 119–136.
- Ol’ha F. Myholynec’. 2004. Ukraïns’ki zakarpats’ki hovirky : teksty. Lira, Užhorod.
- Andrea Moro. 2017. Copular Sentences. The Wiley Blackwell Companion to Syntax, Second Edition (eds M. Everaert and H.C. Riemsdijk)..
- Hanna Nakonečna and Jaroslav Bohdan Rudnyc’kyj. 1940. Ukrainische Mundarten : Südkarpatoukrainisch ; (Lemkisch, Bojkisch und Huzulisch) [Ukrainian dialects: South Carpathian Ukrainian; Lemkian, Bojkian and Huzulian]. Arbeiten aus dem Institut für Lautforschung an der Universität Berlin ; 9. Otto Harrassowitz, Berlin.
- Ivan Zheguc. 2001. Vybrani teksty z hucul’s’koho hovoru v Zakarpatti [Selected texts from the Hutsul dialect in Transcarpathia]. I. Zheguc, Munich.
- Mikhailo Andriiovych Zhovtobriukh, Vitalii M. Rusanivs’kyi, and Vitaliy H. Skliarenko. 1979. Istoriia ukraïns’koï movy. Fonetyka [History of the Ukrainian Language. Phonetics]. Naukova dumka, Kyiv.
- Ivan Zilyns’kyj. 1932. Opis fonetyczny języka ukraińskiego [The Phonetic Description of the Ukrainian Language]. Polska Akademia Umiejętności, Kraków / Komisja Językowa: Prace 19. Nakładem Polskiej Akad. Umięjętności, Kraków.
- Ivan M. Zilyns’kyj. 1933. Karta ukraïns’kych hovoriv: z pojasnennjamy ; mirylo 1:4.000.000. Praci Ukräins’koho Naukovoho Institutu 14. Ukraïns’kyj Naukovyj Instytut, Warszawa.
- Jurij Volodymyrovyč Ševel’ov. 1979. A historical phonology of the Ukrainian language. Historical phonology of the Slavic languages ; 4. Winter, Heidelberg.